若您覺得文章寫得不錯,請點選文章上的廣告,來支持小編,謝謝。
If you like this post, please click the ads on the blog or buy me a coffee. Thank you very much.
此章介紹了人工智慧的定義與起源,以及它的發展與現況。在1956年,科學家在一次的研討會中,提出「人工智慧」一詞,希望機器能夠使用語言、能理解抽象概念、能解決只有人類可解決的問題、能自我改良等。而Alan Turing提出了 Turing Test來檢驗機器是否具有智慧。
世界各大企業持續提供方便的人工智慧工具,例如Google AI Experiments。

第2章人工智慧如何運作
此章介紹了人工智慧如何運作以及機器學習、類神經網路、深度學習的基礎觀念。機器學習、類神經網路、深度學習的關係可參考下圖:

人工智慧研究如何讓機器(電腦)表現得有智慧,於是得先有資料給它進行學習(輸入),讓電腦進一步計算與分析(處理),最後產生結果或功能(輸出),如下圖所示:

機器學習通常分為三種類型:監督式學習(Supervised Learning)、非監督式學習(Unsupervised Learning)、強化學習(Reinforcement Learning)。

深度學習是從類神經網路發展而來的,而類神經網路利用機器來模擬人腦神經系統運作模式。( https://playground.tensorflow.org/ )
類神經網路如下圖所示,含有輸入層(Input Layer)、隱藏層(Hidden Layer)、輸出層(Output Layer)。

AI Experiments 實作體驗
Teachable Machine 網站:https://teachablemachine.withgoogle.com/
Teachable Machine 教學影片:https://www.youtube.com/watch?v=3BhkeY974Rg
操作說明(後續附上連結)
Tensorflow Playground 網站:https://playground.tensorflow.org/
操作說明(後續附上連結)
第3章人工智慧的影像辨識與應用
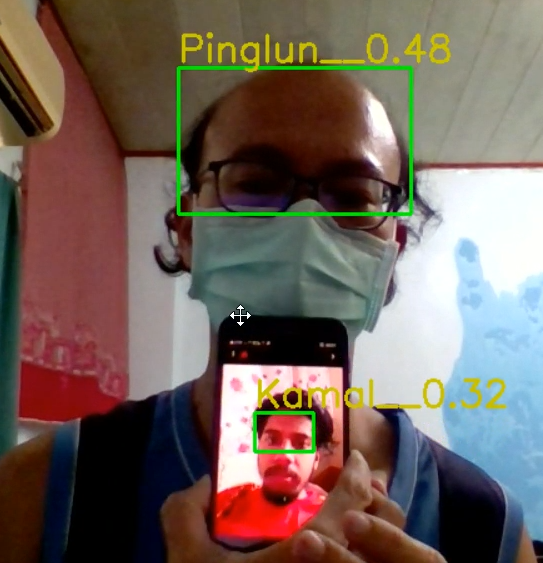
人工智慧影像辨識是研究與展現最多的應用之一,因為視覺很讓人容易感到很多的體驗。
人工智慧影像辨識是研究與展現最多的應用之一,因為視覺很讓人容易感到很多的體驗。
圖像的基本單位為像素,一個像素不見得是正方形,可以是點、線、或是平滑的線。下圖取自 https://en.wikipedia.org/wiki/Pixel。
機器學習的影像資訊處理過程:原始影像 --> 特徵提取 --> 群集分類 --> 辨識學習 --> 模型應用
資料集
MNIST手寫資料集 http://yann.lecun.com/exdb/mnist/
ImageNet 影像資料集 https://www.image-net.org/
影像辨識應用:智慧城市、智慧辦公室、智慧零售、智慧家庭
AI Experiments 實作體驗
Thing Translator 網站:https://experiments.withgoogle.com/thing-translator
操作說明(後續附上連結)
Giorgio Cam 網站:https://experiments.withgoogle.com/giorgio-cam
操作說明(後續附上連結)
Emoji Scavenger Hunt 網站:https://experiments.withgoogle.com/emoji-scavenger
操作說明(後續附上連結)Move Mirror 網站:https://experiments.withgoogle.com/move-mirror
操作說明(後續附上連結)
AutoDraw 網站:https://experiments.withgoogle.com/autodraw
操作說明(後續附上連結)Cartoonify 網站:https://experiments.withgoogle.com/cartoonify
操作說明(後續附上連結)Quick, Draw! 網站:https://experiments.withgoogle.com/quick-draw
操作說明(後續附上連結)Sketch-RNN Demos 網站:https://experiments.withgoogle.com/sketch-rnn-demo
操作說明(後續附上連結)Scrying Pen 網站:https://experiments.withgoogle.com/scrying-pen
操作說明(後續附上連結)Handwriting with a Neural Net 網站:https://experiments.withgoogle.com/handwriting-with-a-neural-net
操作說明(後續附上連結)
聲音介紹,波動。聲波的振幅、聲波的頻率、聲波的波形。
機器學習的聲音資訊處理過程:原始聲音 --> 特徵提取 --> 群集分類 --> 模型應用
各類聲音辨識競賽
AI Experiments 實作體驗
Bird Sounds 網站:https://experiments.withgoogle.com/bird-sounds
操作說明(後續附上連結)
The Infinite Drum Machine 網站:https://experiments.withgoogle.com/drum-machine
操作說明(後續附上連結)
AI Duet 網站:https://experiments.withgoogle.com/ai-duet
操作說明(後續附上連結)
NSynth: Sound Maker 網站:https://experiments.withgoogle.com/sound-maker
操作說明(後續附上連結)
Beat Blender 網站:https://experiments.withgoogle.com/beat-blender
操作說明(後續附上連結)
Melody Mixer 網站:https://experiments.withgoogle.com/melody-mixer
操作說明(後續附上連結)
第5章人工智慧的文字、語言技術與應用
自然語言處理過程:文字或語音資料 --> 字詞分析 --> 語意理解 --> 生成語言
這看起來好像很輕鬆容易,但對電腦而言這不是很容易,這件事情和符號接地問題(https://en.wikipedia.org/wiki/Symbol_grounding_problem)有關。
聊天機器人「小冰」
AI Experiments 實作體驗
Semantris 網站:https://experiments.withgoogle.com/semantris
操作說明(後續附上連結)
Talk to Books 網站:https://experiments.withgoogle.com/talk-to-books
操作說明(後續附上連結)
Font Map 網站:https://experiments.withgoogle.com/font-map
操作說明(後續附上連結)
Fontjoy 網站:https://experiments.withgoogle.com/fontjoy
操作說明(後續附上連結)
Scribbling Speech 網站:https://experiments.withgoogle.com/scribbling-speech
操作說明(後續附上連結)
第6章人工智慧創意應用
AI和硬體整合(如Arduino、Microbit、ESP32、Raspberry PI等)後,產生了虛擬整合的智慧物聯網(AIoT)。
AI Experiments 實作體驗
Morse + WaveNet Starter Code 網站:https://experiments.withgoogle.com/morse-speak-demo
操作說明(後續附上連結)
Rock-Paper-Scissor Machine 網站:https://experiments.withgoogle.com/rock-paper-scissors
操作說明(後續附上連結)
NSynth Super 網站:https://experiments.withgoogle.com/nsynth-super
操作說明(後續附上連結)
Sound-Controlled Intergalactic Teddy 網站:https://experiments.withgoogle.com/sound-teddy
操作說明(後續附上連結)
Objectifier Spatial Programming 網站:https://experiments.withgoogle.com/objectifier-spatial-programming
Semi-Conductor 網站:https://experiments.withgoogle.com/semi-conductor
操作說明(後續附上連結)
Imaginary Soundcape 網站:https://experiments.withgoogle.com/imaginary-soundscape
操作說明(後續附上連結)